
As I covered in Part 1, identifying an issue is only half the battle with any infrastructure problem. You must have a key brain trust within the team that can help quickly analyze and resolve that problem, no matter what it is. In this part, we will look at how to connect the application monitoring to the appropriate teams and utilize modern tools to make sure the right team members know about an issue in real time and are engaged to resolve it immediately.
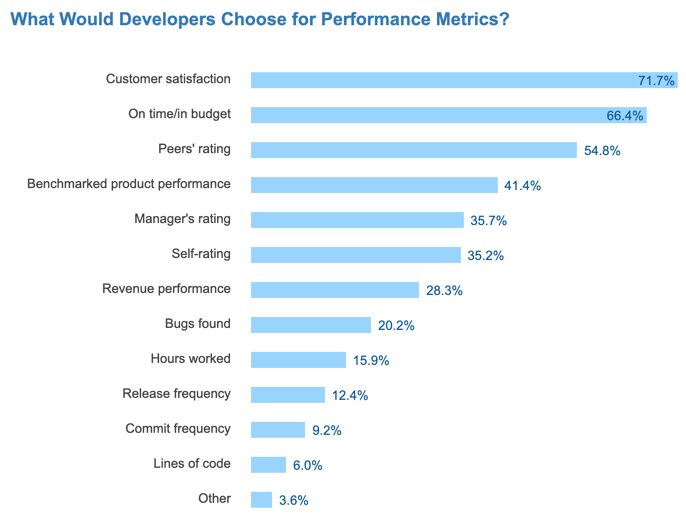
The correlation between customer impact and developer job satisfaction is key. The top employers attract the best developers because they see the direct impact of the work on their customers. In fact, from tens of thousands of developers that took the Stack Overflow Developer Survey 2017, we see that over 70% of developers say that customer satisfaction is the top metric they want to be measured on to effectively gauge their performance. It outranks other measurements, including being on time and in budget, peer ratings, or manager ratings.
One of the top ways to improve customer satisfaction is by reducing downtime and increasing overall support responsiveness when an issue does arise. This is where the rubber meets the road and you can head off or significantly reduce downtime through the use of the right tools. There are a variety of technology choices available, but we will focus on the 2 that our team chose to implement because they fit well with our corporate tools and strategy: PagerDuty and Slack.
PagerDuty
PagerDuty enables DevOps teams to focus on high-performing apps with quality customer experiences. They do this through real-time alerts and visibility into critical systems and applications, allowing operations teams to quickly detect, triage, and resolve incidents from development through production.
- Stack Visibility: Aggregate data from development and production while detecting performance issues across the application release cycle.
- Deployment Impact and Response: Understand new code deployments for rapid identification of issues, and implement code rollback to restore service.
- Event Intelligence: Automatically suppress non-actionable events and group what’s actionable into a centralized view to focus on issues that matter.
- Alert Management: Centralize alerts and notify your team of critical incidents in the way that works best for each individual in an automated fashion. You can surface the right remediation information, troubleshoot, and recruit teammates as needed to resolve with ease.
- Easy Scheduling and Automated Escalations: Scheduling helps you plan employee resources to support critical apps both during and after hours. Incidents are routed to the right person at the right time.
- Real-Time Collaboration: Mobilize additional experts dynamically to address incidents in real time through integration with a variety of tools, conferencing solutions, and ticketing systems.
- Continuous Feedback Loop: Using analytics and learning, you can continuously improve the efficiency of your response, as well as the resiliency of your services.
What this ultimately means is less time spent on operations work, so your developers can spend more time building what matters to drive customer value.
Slack
Slack has become our team’s go-to collaboration tool cutting down on email and helping to improve the overall team dynamic, especially when working in remote locations. The beauty of combining PagerDuty and Slack is the ability to drive real-time ops from Slack in an innovative way, since our developers already use on a daily basis.
Real-time ops requires teams to work where they are. With this integration, users can run a PagerDuty incident response play from a Slack notification and add responders on-the-fly. Create, reassign, escalate, or gather more context about an incident—all from within Slack.
This integration also enables teams to quickly and easily override PagerDuty schedules, and view up-to-date on-call information and timelines all from within Slack.
- Slack can act as a PagerDuty interface.
- Respond through Slack by creating, reassigning, escalating, or running an incident response play.
- Loop in additional responders and add response help directly from a Slack notification.
- Use Slack integration features via a Slackbot.
- Create or point to a Slack channel directly from PagerDuty and automatically invite responders to the right channel.
- Drive postmortems and capture all discussions and actions in the channel.
- Stay informed about your on-call schedules by viewing them from Slack.<
Conclusion
The knockout punch is when you combine all 3 of these tools into an integrated approach for your DevOps team. Use New Relic to monitor and integrate with PagerDuty to trigger alerts directly in Slack channels for your response team to address immediately. This provides for a DevOps team to take on 24/7 support in an efficient manner, which becomes especially critical as applications are transitioned to cloud environments.
Through this implementation, we were able to overcome several challenges and see multiple benefits:
- We reduced the time when we became aware of an outage from 1-4 hours to 1-10 minutes, allowing us to act faster to resolve a problem and increase application availability.
- We now know instantly if a service/application goes down vs. finding out when a customer reports an issue.
- We are able to immediately engage the right contacts to escalate automatically vs. waiting for team to engage and respond.
- We can provide a full history of downtime/issues for postmortems vs. unstructured tracking of issues and downtimes.
- We were able to automate functions and work our way, with our tools via seamless integration
These automation tools allow for our DevOps teams to focus on development that matters most, while increasing overall customer satisfaction for the production applications and reducing downtime.




{kind=link}